Driving SMARTS 2022
The Driving SMARTS 2022 is a benchmark used in the NeurIPS 2022 Driving SMARTS competition.
Objective
Objective is to develop a single policy capable of controlling single-agent or multi-agent to complete different driving scenarios in the driving-smarts-v2022 environment.
Refer to driving_smarts_2022_env() for environment details.
In each driving scenario, the ego-agents must drive towards their respective mission goal locations. Each agent’s mission goal is given in the observation returned by the environment at each time step.
The mission goal could be accessed as observation.ego_vehicle_state.mission.goal.position which gives an (x, y, z) map coordinate of the goal location.
Any method such as reinforcement learning, offline reinforcement learning, behavior cloning, generative models, predictive models, etc, may be used to develop the policy.
The scenario names and their missions are as follows. The desired task execution is illustrated by a trained baseline agent, which uses PPO algorithm from Stable Baselines3 reinforcement learning library.
- 1_to_2lane_left_turn_c
A single ego agent must make a left turn at an unprotected cross-junction.
- 1_to_2lane_left_turn_t
A single ego agent must make a left turn at an unprotected T-junction.
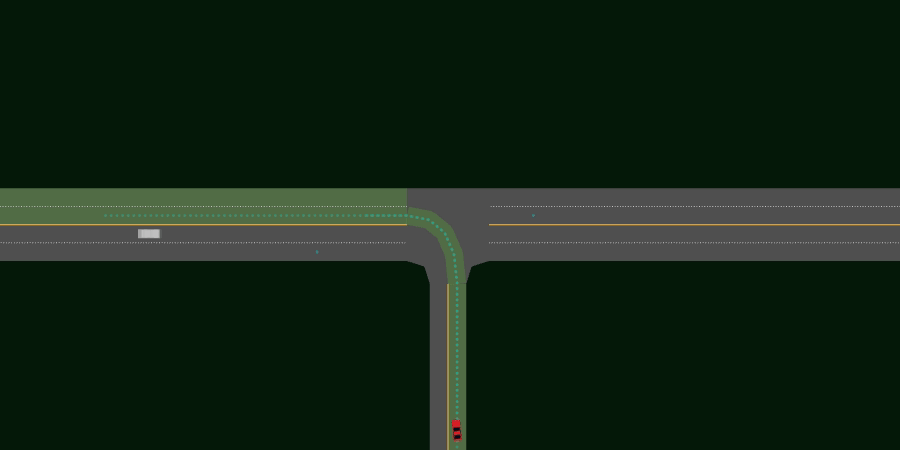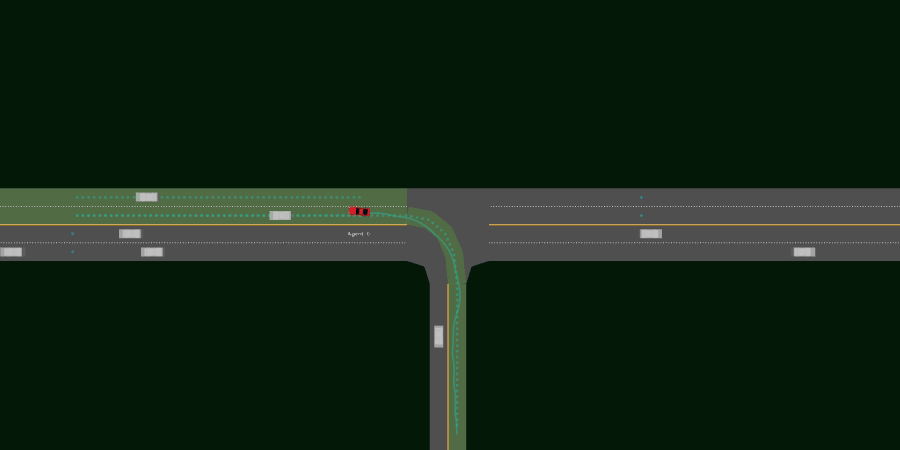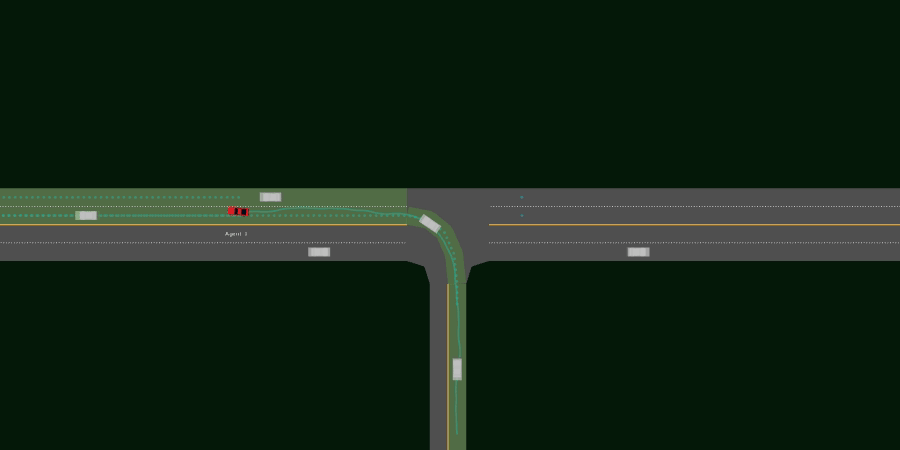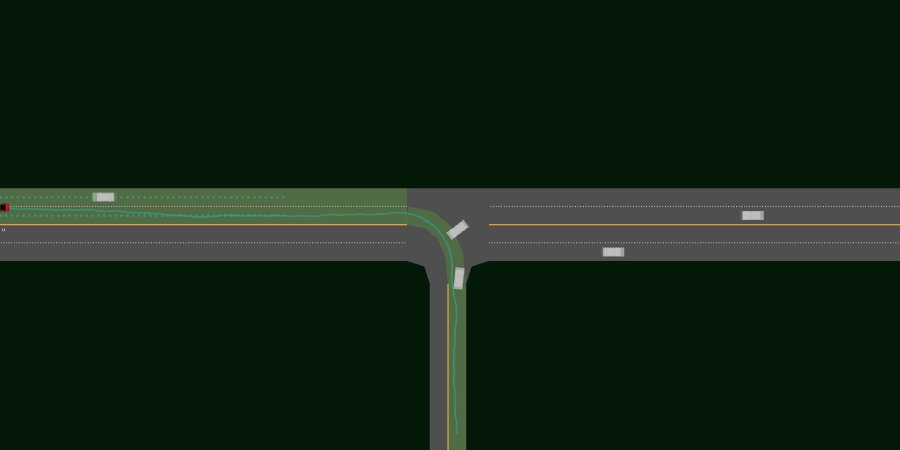
- 3lane_merge_multi_agent
One ego agent must merge onto a 3-lane highway from an on-ramp, while another agent must drive on the highway yielding appropriately to traffic from the on-ramp.

- 3lane_merge_single_agent
One ego agent must merge onto a 3-lane highway from an on-ramp.

- 3lane_cruise_multi_agent
Three ego agents must cruise along a 3-lane highway with traffic.

- 3lane_cruise_single_agent
One ego agents must cruise along a 3-lane highway with traffic.

- 3lane_cut_in
One ego agent must navigate (either slow down or change lane) when its path is cut-in by another traffic vehicle.

- 3lane_overtake
One ego agent, while driving along a 3-lane highway, must overtake a column of slow moving traffic vehicles and return to the same lane which it started at.
Observation space
The underlying environment returns raw observations of type Observation at each time point for each ego agent.
Action space
This benchmark allows ego agents to use any one of the following action spaces.
Zoo agents
See the list of available zoo agents which are compatible with this benchmark. A compatible zoo agent can be evaluated in this benchmark as follows.
$ cd <path>/SMARTS
$ scl zoo install <agent path>
# e.g., scl zoo install zoo/policies/interaction_aware_motion_prediction
$ scl benchmark run driving_smarts_2022==0.0 <agent_locator> --auto_install
# e.g., scl benchmark run driving_smarts_2022==0.0 zoo.policies:interaction-aware-motion-prediction-agent-v0 --auto-install